Journal Article about MofDB
- Publication in the Journal of Chemical Engineering Data:
MOFX-DB: An Online Database of Computational Adsorption Data for Nanoporous Materials - PDF:
acs.jced.2c00583.pdf
Purpose
MofDB is an api/webfront-end and database I built for the Snurr Research Group at Northwestern. The database contains the results of high throughput screenings of metal organic frameworks with the goal of finding materials that will be helpful for gas separations like Xe/Kr Co2 adsorption etc.
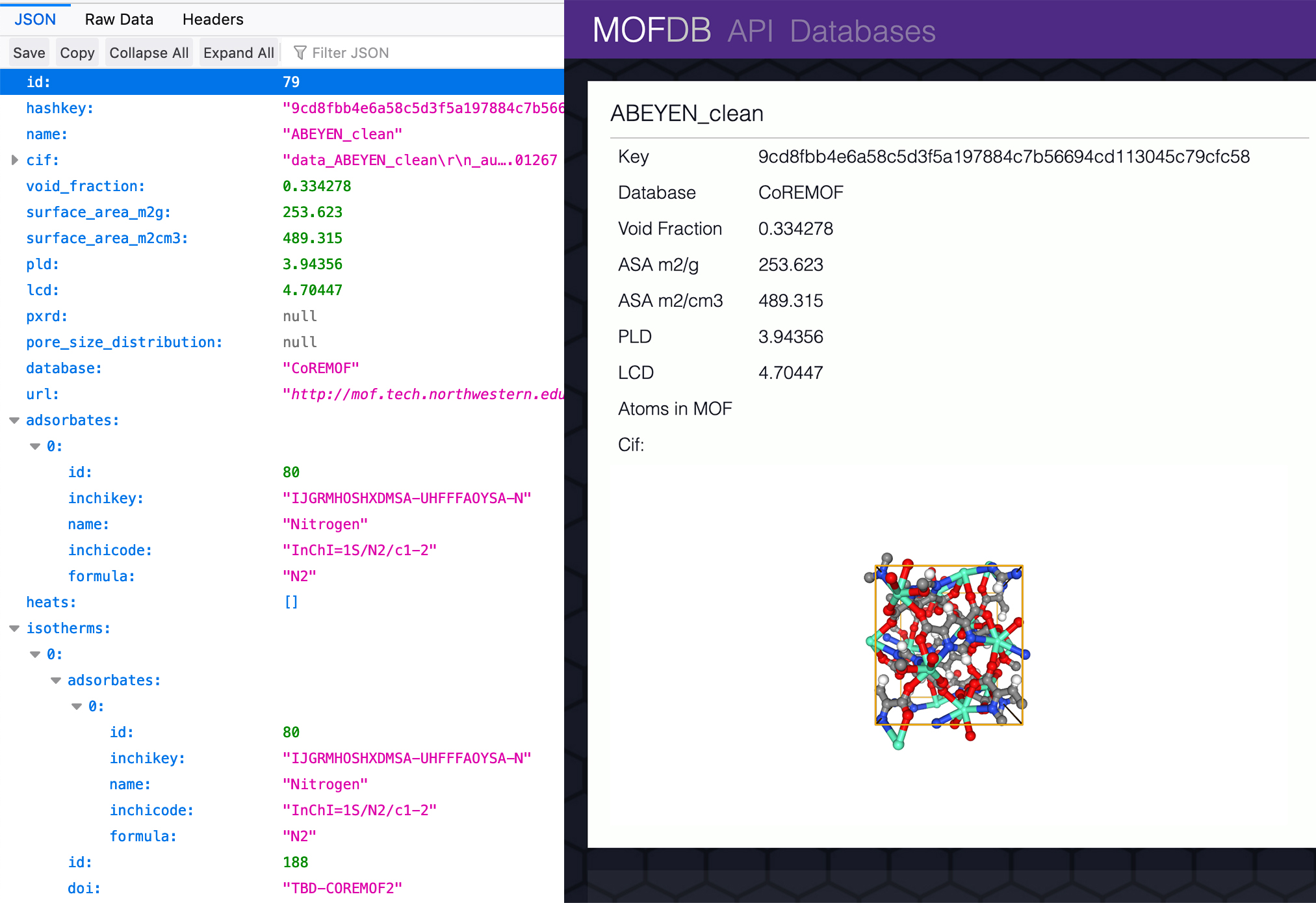
The database provides a way to share data with other researchers in an easily accesible json format that was developed by NIST for their own database of similar data. This makes data interoperable for researchers using data from both systems.
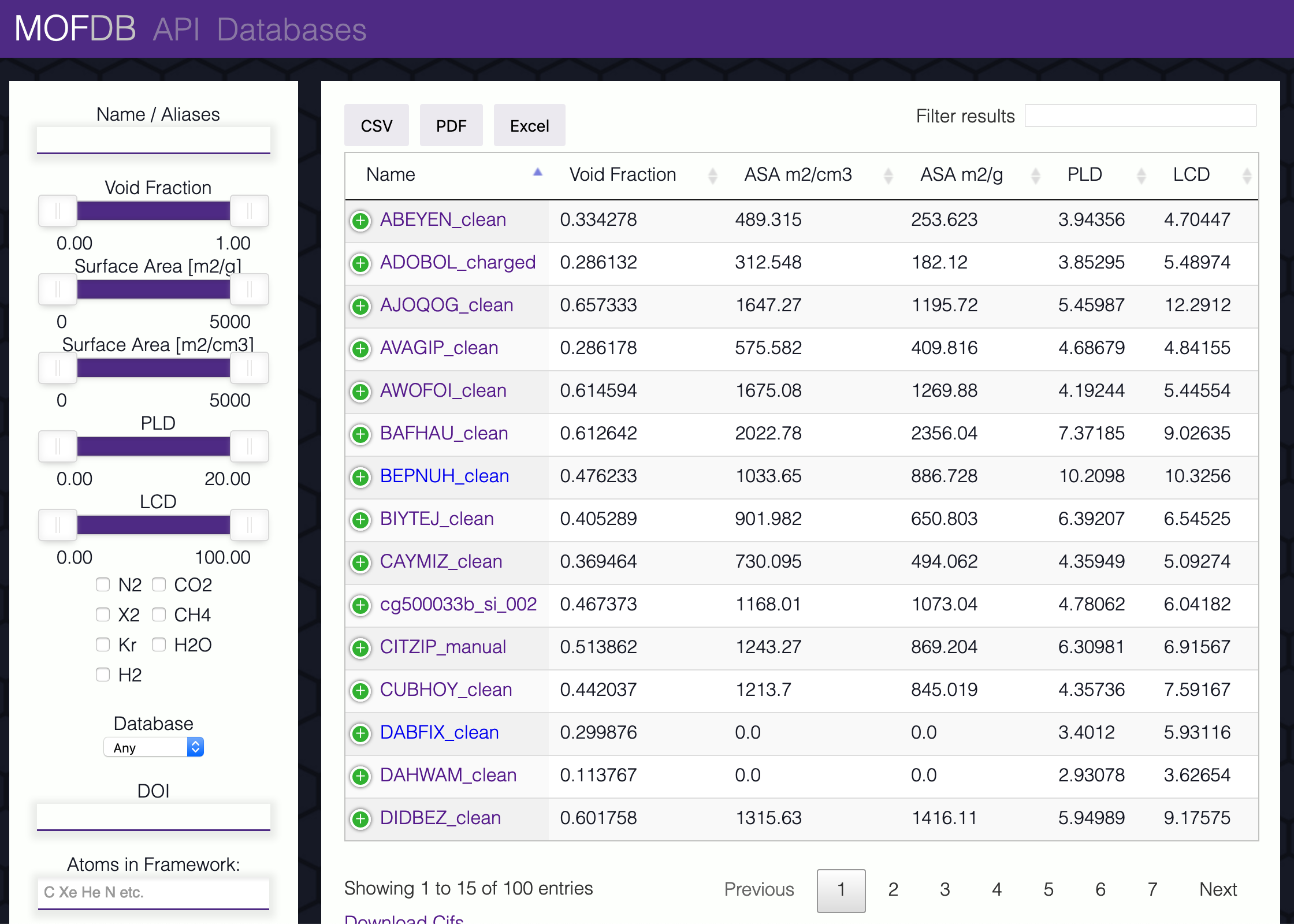
Front End
The front end of mofDB is a essentially a collection of filters (left column) that trigger a new request to the api. When the filters are adjusted the api is called and the table (right column) you see on the homepage is swapped out.
API
The biggest challenge of the mofDB project was scale. There are easily 400,000 materials with a dozen properties each, and a handful of children models with even more data. A common use case for researchers is to download all of the data from a given set of materials (often ~100k) within mofDB. This means we need to be able to compile and serve that information in near real time. This is acheived by caching a json copy of all materials so that a query can simply concat them together before devivering them to the user. Before this caching it took about ~10ms * # of materials. Which was clearly too slow for numbers in the 100,000s.
The api also provides all the same search functions as the front-end (which of course uses the api). Like filtering by material properties, what atoms are present in the material, and what isotherms the material has. The api is documented here.
All front-end routes are also available as json by adding the .json suffix.